



※当サイトはアフィリエイトプログラムによる収益を得ています。
独立GPU無しのノートPCで、ローカルLLMを動かしてみた【LM Studio使用】

ここでは、独立GPUが搭載されていない3台のノートパソコンで、ローカルLLMを動かし、どのくらいのスペックであれば快適に動くのかを簡単にテストしました。なお、テストでは、LM Studioを使用しています。
LM Studioとは?
LM Studioとは、ローカル環境(自分のPC上)で、LLM(大規模言語モデル)やSLM(小規模言語モデル)を実行・操作するためのアプリです。Llama、Gemma、DeepSeekなどのモデルを、切り替えて使用することができます。
テストに使ったノートPC
テストに使ったノートPCは、次の3台です。旧世代のCore i7-1360Pと、最新世代のCore Ultra 7 255HおよびCore Ultra 7 258Vを用いました。Ryzen AIのプロセッサーでもテストしたかったのですが、ちょうどいいPCが手元に無かったので、また今度にでもテストします。
| CPU | メモリ | |
| デル Inspiron 16 (5630) | Core i7-1360P | 16GB |
| HP OmniBook 7 14-fr | Core Ultra 7 255H | 32GB |
| ThinkPad X1 Carbon Gen 13 | Core Ultra 7 258V | 32GB |
なお、ローカルLLMを動かす場合、GPU性能が大事なので、各CPUのグラフィックス性能を下に掲載しておきます。
LM Studioの導入
LM Studioは、「こちらのサイト」からダウンロードできます。インストールはウィザード通り行えばOKです。
最初は、2025年8月5日にリリースされたgpt-oss-20bのモデルのダウンロードを推奨されます。その後は、好きなモデルをダウンロードすることもできます。
後はダウンロードしたモデルを選択し、そのモデルに対してチャット形式で質問をすることで、結果を返してくれます。
テスト内容
テストでは、「ノートパソコンにNPUは必要ですか?200字前後で答えてください。」という質問を、いくつかのモデルで実行し、そのときのCPU/GPU/NPU負荷や、トークン生成速度を計測しました。
※トークンとは、文章を分割した小さな単位のことで、日本語だと、モデルにもよりますが1トークンがだいたい1.5~2.5文字になります。
基本的にはGPUで処理
いくつかモデルを動かしてみましたが、GPUに大きな負荷がかかっていました。CPUも使いますが、負荷はそれほど高くありません。また、現在のところ、LM Studioだと、NPUを使うモデルはなさそうでした。
ただ、LM Studioでは使えませんでしたが、DeepSeek R1 DistilledではNPUで動作するので、そのうちLM Studioでも、NPUで動作するモデルが加わるかもしれません。
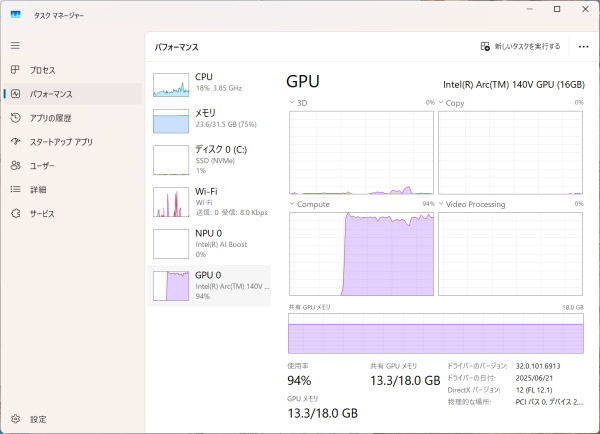
余談
LM Studioと同様のアプリとして、Ollamaというのもありますが、Ollamaだと、モデルを使って推論をするときに、GPUが使われず、CPUのみで処理していたので、今回は、LM Studioを使いました。
パラメータと量子化形式によって必要なメモリが変わる
パソコンに必要なメモリは、動かすAIのモデルによって異なります。
各モデルは「12B」や「20B」などのパラメータを持っており、理論上は、このパラメータ数が多ければ多いほど、複雑で高度なタスクがこなせるようになります。なお、「B」はビリオン(=10億)の略です。モデル名に、12Bや20Bといった文字が入っているので分かりやすいです。このパラメータが多ければ多いほど、メモリ容量がたくさん必要になります。
また、「Q8」や「Q4」といったように記載される量子化(圧縮みたいなイメージ)が行われており、これによっても必要なメモリ容量は変わります。LM Studioの場合、Download Optionsのモデル名の横に、量子化形式が書かれています。例えばQ4だと4bitなので、標準のFP32(32bit)と比べると、かなり小さく量子化されていることになります。このビット数が小さければ小さいほど、必要なメモリ容量は減ります。ただし、その分推論の精度は落ちます。
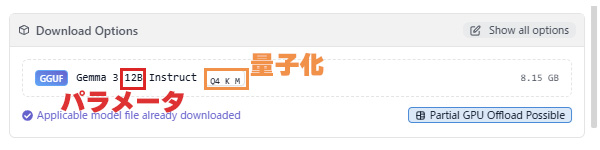
どのくらのメモリで、どのくらいのモデルが動くかについては、次の項目を見て下さい。
各モデルのトークン生成速度
次に、各モデルを動かしたときの結果を掲載します。
gpt-oss-20b【Open AI社】
まずは、LM Studioをインストールすると最初にダウンロードを促される「gpt-oss-20b」のモデルで、トークン生成速度を計測しました。なお、量子化形式はMXFP4となっていますが、4bit浮動小数点のようです。
このモデルは、20Bとパラメーターが多いので、16GBメモリを搭載したCore i7-1360Pでは動作しませんでした。
その他のPCのトークン生成速度は以下の通りで、GPU性能の差がそのまま出ているような形です。
Core Ultra 7 258V搭載PCで、モデルに質問をして、回答ももらっているときの様子は下の通りです。クラウドのChat GPTよりは遅いですが、全然待てる範囲です。
回答内容の精度については、主観では、まずまずだと思います。ただ、やはりクラウドのChat GPTの精度は高いです。
gemma-3-12b【Google社】
先ほどのモデルは、16GBメモリを搭載したCore i7-1360Pでは動作しなかったので、次は、「12B」のパラメーター、「4bit」の量子化のgemma-3-12bで試してみました。ただ、こちらもCore i7-1360Pでは動作しませんでした。
他のPCについては動きましたが、トークン生成速度は先ほどより遅かったです。体感でも、少し遅さを感じます。
deepseek-r1-0528-qwen3-8b【DeepSeek社】
次に、もっと小規模な「8B」、「4bit」のdeepseek-r1-0528-qwen3-8bでテストしたところ、16
GBのCore i7-1360Pでも動きました。速度はCore i7-1360Pだとやや遅さを感じます。
gemma-3-27b【Google社】
次に27B(4bit)と、今回のテストの中では大きなモデルでテストしましたが、トークン生成速度は遅く、大分待たされ、ストレスを感じます。
llama-3.3-70b【Meta社】
最後に70B(3bit)のモデルをテストしてみましたが、こちらはモデルが大きすぎて動作しませんでした。
まとめ
今回、独立GPUを搭載していない普通のノートパソコンで、LM Studioを使って、ローカルLLM/SLMを動かし、どのくらいのスペックであれば、快適に動くかをテストしました。
推論時は、GPUの負荷が高かったので、内蔵グラフィックスの性能の高いCPUがおすすめです。具体的には、Core Ultra 7 258Vが速かったです。Core Ultra 255Hでも悪くないです。なお、現時点では、NPUで動くモデルはLM Studioにはなさそうだったので、NPUは無くても大丈夫です。ただ、今後、対応するかもしれないので、NPUのあるCPUでもいいと思います。
メモリは、16GBだと動かせるモデルが大分限られてくるので、比較的大きいモデルが動く32GBがいいと思います。32GBあれば、割と動かせるモデルは多いです。64GBにすれば、より大規模なモデルも動きますが、CPU内蔵のグラフィックスでは性能不足な感じはあります。でも、32GBメモリだと、大きなモデルを使っていると空きメモリがほとんどないので、64GBでもいいとは思います。
総合的に考えると、独立GPUを搭載していないノートPCの場合、Core Ultra 7 258V、32GBメモリのノートPCが、現状ではローカルLLMを実行するのに適した構成かと思います。CPUは、Core Ultra 255Hでもいいです。今回試してはいませんが、Ryzen AI 9 HX 370やRyzen 7 8845HSも内蔵グラフィックス性能が高いのでいいと思います。Core Ultra 7 258Vはメモリが統合されているので、これ以上増やせませんが、Core Ultra 255Hなどなら、(スロットメモリなら)64GBのメモリを搭載することもできます。

1975年生まれ。電子・情報系の大学院を修了。
2000年にシステムインテグレーターの企業へ就職し、主にサーバーの設計・構築を担当。2006年に「the比較」のサイトを立ち上げて運営を開始し、2010年に独立。
毎年、50台前後のパソコンを購入して検証。メーカーさんからお借りしているパソコンを合わせると、毎年合計約150台のパソコンの実機をテストしレビュー記事を執筆。
関連ページ







