



※当サイトはアフィリエイトプログラムによる収益を得ています。
独立GPU搭載ノートPCで、ローカルLLMを動かすと速くなる?【LM Studio使用】

ここでは、独立GPUが搭載されたノートパソコンにて、LM StudioでローカルLLMを動かし、独立GPUが非搭載のノートパソコンと比べて、どのくらい速くなるのかをテストしてみました。
LM Studioとは?
LM Studioとは、ローカル環境(自分のPC上)で、LLM(大規模言語モデル)やSLM(小規模言語モデル)を実行・操作するためのアプリです。Llama、Gemma、DeepSeekなどのモデルを、切り替えて使用することができます。
テストに使ったノートPC
テストに使った独立GPU搭載のノートPCは、次通りで、CPUにはCore Ultra 7 155H、GPUにはGeForce RTX 4060 Laptop、メモリは32GBを搭載しています。

また、比較のために、独立GPUを搭載していない以下のノートPCでも、同じテストを行いました。いずれもメモリは32GBです。
| CPU | メモリ | |
| Acer Swift Go | Core Ultra 7 155H | 32GB |
| HP OmniBook 7 14-fr | Core Ultra 7 255H | 32GB |
| IdeaPad Pro 5 Gen 10 | Ryzen AI 7 350 | 32GB |
なお、各PCの、CPUおよびGPU性能の指標となるベンチマークスコアを下に掲載しておきます。
LM Studioの導入とモデルの選択
LM Studioは、「こちらのサイト」からダウンロードできます。
最初は、2025年8月5日にリリースされたgpt-oss-20bのモデルのダウンロードが推奨されます。
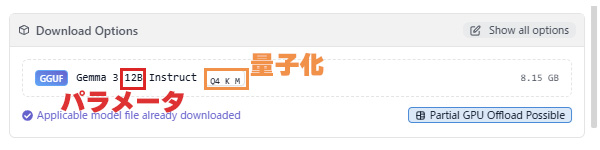
その後は、好きなモデルをダウンロードすることもできます。各モデルは「12B」や「20B」などのパラメータを持っており、理論上は、このパラメータ数が多ければ多いほど、複雑で高度なタスクがこなせるようになります。また、「Q8」や「Q4」といったように記載される量子化(圧縮みたいなイメージ)が行われており、これによりモデルサイズが小さくなり、より少ないメモリでも動くようになります。
テスト内容
テストでは、「ノートパソコンにNPUは必要ですか?200字前後で答えてください。」という質問を、いくつかのモデルで実行し、そのときのトークン生成速度と、最初のトークンが出始めるまでの時間を計測しました。
※トークンとは、文章を分割した小さな単位のことで、日本語だと、モデルにもよりますが1トークンがだいたい1.5~2.5文字になります。
独立GPU搭載PCはGPUが優先で、次がCPU
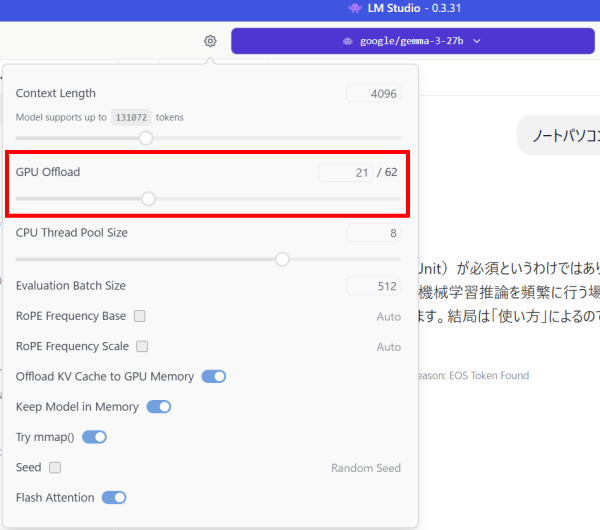
試しに、独立GPUを搭載したPCで、「27B(量子化4bit)」モデルをロードしてみます。
今回、GeForce RTX 4060 Laptopのモデルを搭載していますが、VRAMは8GBです。この8GBに収まる分だけ、独立GPUのVRAMに、レイヤーのパラメータがオフロードされていました。
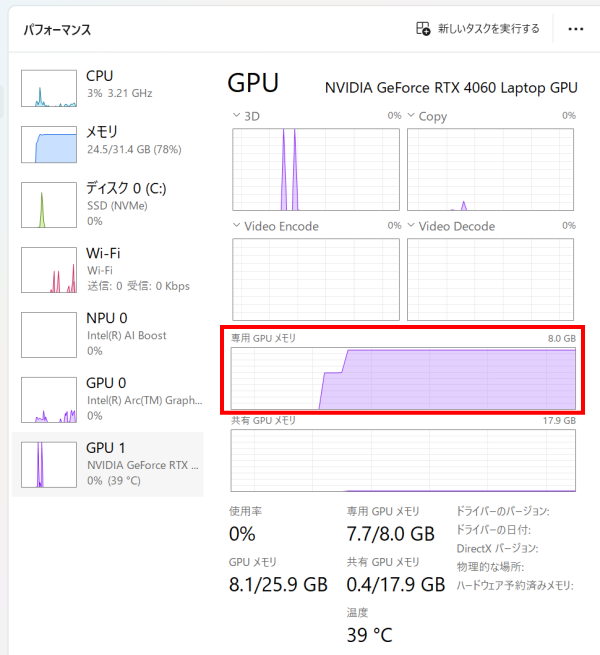
GPU Offloadの設定を見ても、「62」のうち「21」のパラメータが、独立GPUにロードされているのが分かります。なお、ここは自分で設定を変更することが可能です。
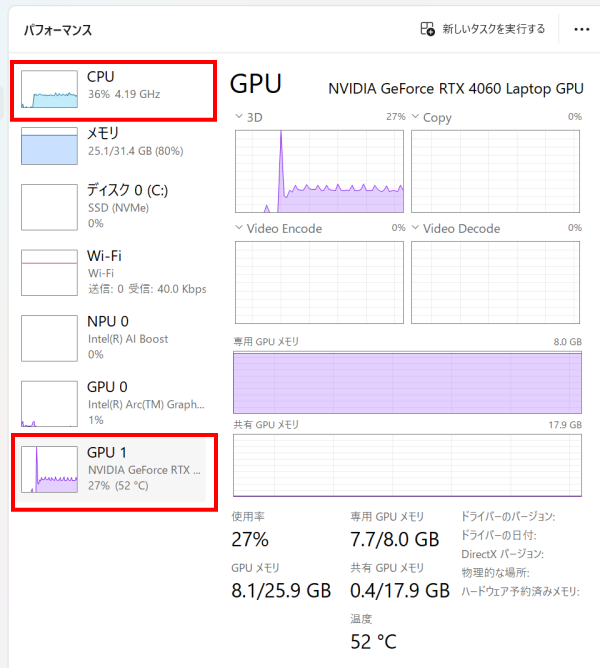
次に、推論を実行してみると(AIに何か質問をしてみると)、独立GPUにオフロードされた分はGPUで処理していますが、残った部分についてはCPUで処理していました。CPU内蔵のGPUは使われないようです(独立GPUと、内蔵GPUの両方が使えるようにはなっていないようです。なお、独立GPUが無いモデルは、内蔵GPUにオフロードすることが可能です)。また、NPUも使われていません。
各モデルのトークン生成速度
次に、各モデルを動かしたときの速度の計測結果を掲載します。
gpt-oss-20b【Open AI社】
まずは、LM Studioをインストールすると最初にダウンロードを促される「20B」の「gpt-oss-20b」のモデルで、「トークン生成速度」および「最初のトークンまでの時間」を計測しました。
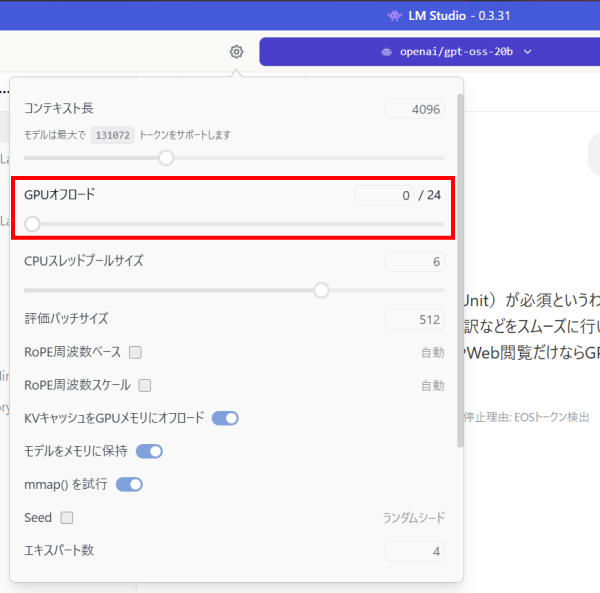
なお、Ryzen AI 7 350搭載PCは、初期設定ではGPUオフロードが「0」となっており、動作時にGPUが使われておらず、最初のトークンが表示されるまでの時間がやや長くなっていました。そのため、Ryzen AI 7 350搭載PCは、GPUオフロードを最大の「24」にしています。
なお、他のノートPCの初期設定は、Core Ultra 7 155搭載PCが「23」、他はいずれも「24」になっており、この初期設定のまま計測しています。「24」の場合は、すべてGPUにオフロードされることになります。
結果は以下の通りです。
上のグラフを見ると、Core Ultra 7 155 + RTX4060を搭載したノートPCは、Core Ultra 7 155Hのみ搭載したノートPCより大分速かったです。グラフィック性能の差がそのまま出ているような感じでした。ただ、Ryzen AI 7 350に関しては、最初のトークンが表示されるまでの時間は結構速かったです。
gemma-3-27b【Google社】
次に、「27B」の「gemma-3-27b」のモデルで同じことを試してみます。
このモデル場合、Core Ultra 7 155 + RTX4060搭載PCでのGPU Offload値は、「21」になっていました。
その他のPCのGPU Offloadの初期値は、Core Ultra 7 155のみ搭載したPCが「44」、Core Ultra 7 255搭載PCが「50」でした。
Ryzen AI 7 350は、初期設定では「0」だったので、ここでは「44」にしています。なお、「50」にしたらモデルが読み込めませんでした。
結果は以下の通りです。
Core Ultra 7 155 + RTX4060が最も速かったですが、すべてGPUにオフロードされていないため、他のCPUとの差は大分縮まりました。ただ、いずれもトークン生成速度が遅く、ややストレスがたまります。「27B」くらいのモデルを動かすなら、もっとVRAMの多い独立GPUを搭載したノートPCか、Ryzen AI Max+ 395にたくさんメモリを搭載したPCのほうがいいかなと思います。
まとめ
今回、独立GPUを搭載したノートパソコンで、LM Studioを使って、ローカルLLMを動かし、どのくらい速くなるかをテストしました。
LLMのモデルサイズが小さく、すべてGPUにオフロードできる場合については、独立GPUを搭載したPCは、非常に速かったです。
モデルが大きく、すべてGPUにオフロード出来ない場合、残りはCPUで処理していたので、独立GPUを搭載していないPCと比べて、差は大分縮まり、思ったほど速くはありませんでした。また、トークン生成速度が遅く、ストレスを感じます。モデルが大きい場合、もっとVRAMの多い独立GPUを搭載したノートPCか、Ryzen AI Max+ 395にたくさんメモリを搭載したノートPCのほうがいいかなと思います。

1975年生まれ。電子・情報系の大学院を修了。
2000年にシステムインテグレーターの企業へ就職し、主にサーバーの設計・構築を担当。2006年に「the比較」のサイトを立ち上げて運営を開始し、2010年に独立。
毎年、50台前後のパソコンを購入して検証。メーカーさんからお借りしているパソコンを合わせると、毎年合計約150台のパソコンの実機をテストしレビュー記事を執筆。
関連ページ





